

Table of contents
What’s the Alexandria Library
It’s an attempt to organize in a folder hierarchy thousands of great articles sourced from Hacker News. Its main purpose is to help you to discover interesting discussions and articles over a topic. You can also hit the /random page to randomly find a topic.
In my last blog post, I was explaining how I’ve extracted more than 100 000 popular articles sourced from Hacker News.
With all these articles, I’ve built HN Recommend, a recommendation engine for Hacker News posts. Let me introduce its successor: The Alexandria library, named after the famous Great Library of Alexandria in Alexandria, Egypt.
Explore a collection of 8000 organized folders, each containing ~20 great articles.
The big how?
Imagine having to organize tens of thousands of articles accumulated over the years. What can you do? Here are three solutions I found:
- Human labour. If I had a company, I could have recruited 2–3 interns, promised them an enriching internship, and asked them to sort the archives. But I don’t have a company, so let’s move on to the second solution.
- There are a lot of software programs that automatically sorts your documents for a utopian paperless world. They work by tagging keywords, finding the correspondent and guessing the date for each document. Then, they construct the folder hierarchy with these attributes. Unfortunately, articles rarely have a correspondent unless they are a rant about something. So I have ditched this one too.
- Starting to lose hope? Have you considered AI? Everyone’s jumping on the AI hype train, so why not us? Let’s utilize embeddings and my own carefully researched solution: the Distributed and Inverted Clustering using K-means (or for the aficionados, the DICK stack)
But what’s an embedding already?
To learn more about embeddings, I recommend you this simple introduction (sourced from the Alexandria library). In summary, an embedding is the representation of a real-world concept (music, text, image) in the form of a vector. The main advantage is that related items will have similar vectors. This means we can compute the Euclidean distance between vectors to find the most related one.
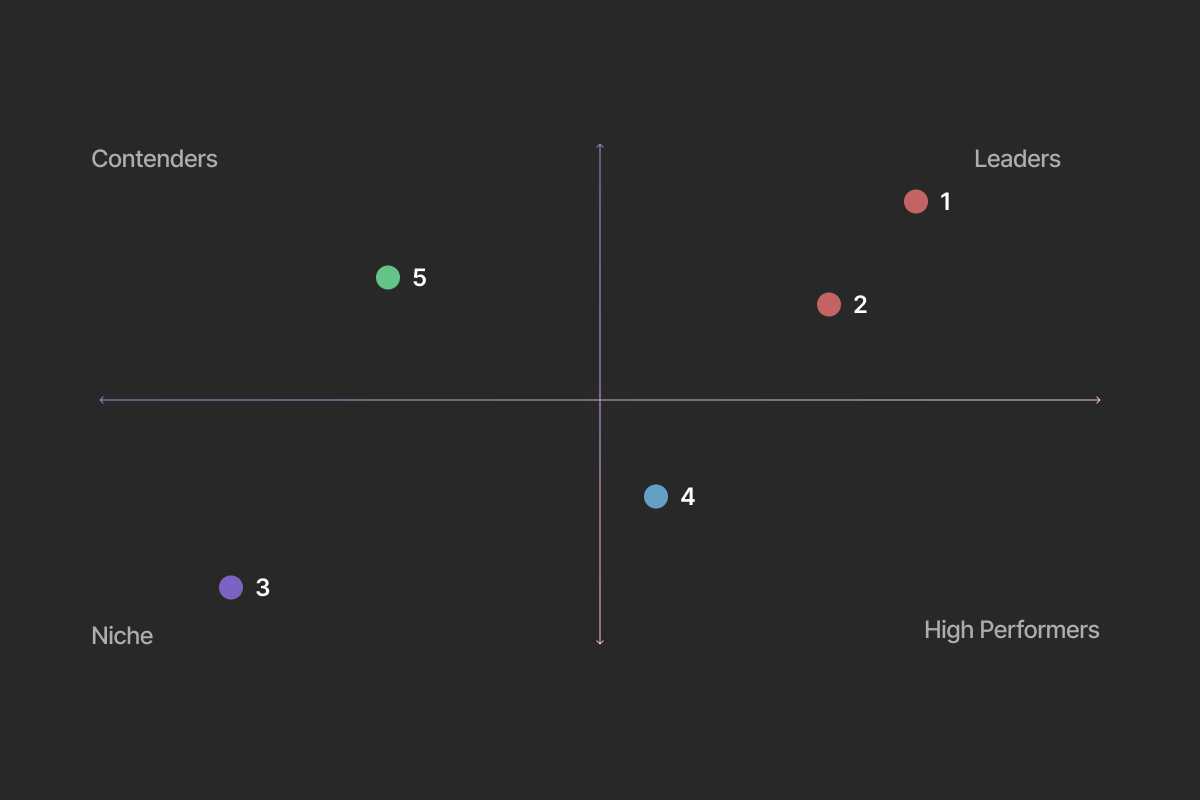
As an example, embeddings are very similar to the 2D charts made by six figures to discuss « strategic » choices. On one hand, item 1 and item 2 are similar, on the other hand, they are extremely different from item 3.
Well, embeddings follow the same concept. The proximity in the mapping indicates the relatedness of the texts. Also, since I don’t have a PhD in maths, we will use a pre-made model from OpenAI (like 95% of AI startups) to compute these embeddings.
What’s the « the Distributed and Inverted Clustering using K-means » method?
As mentioned in the last paragraph, items close to each other are related. So why can’t we use this feature to build our folders? Let’s go back to the previous image, but without the corporate nonsense.
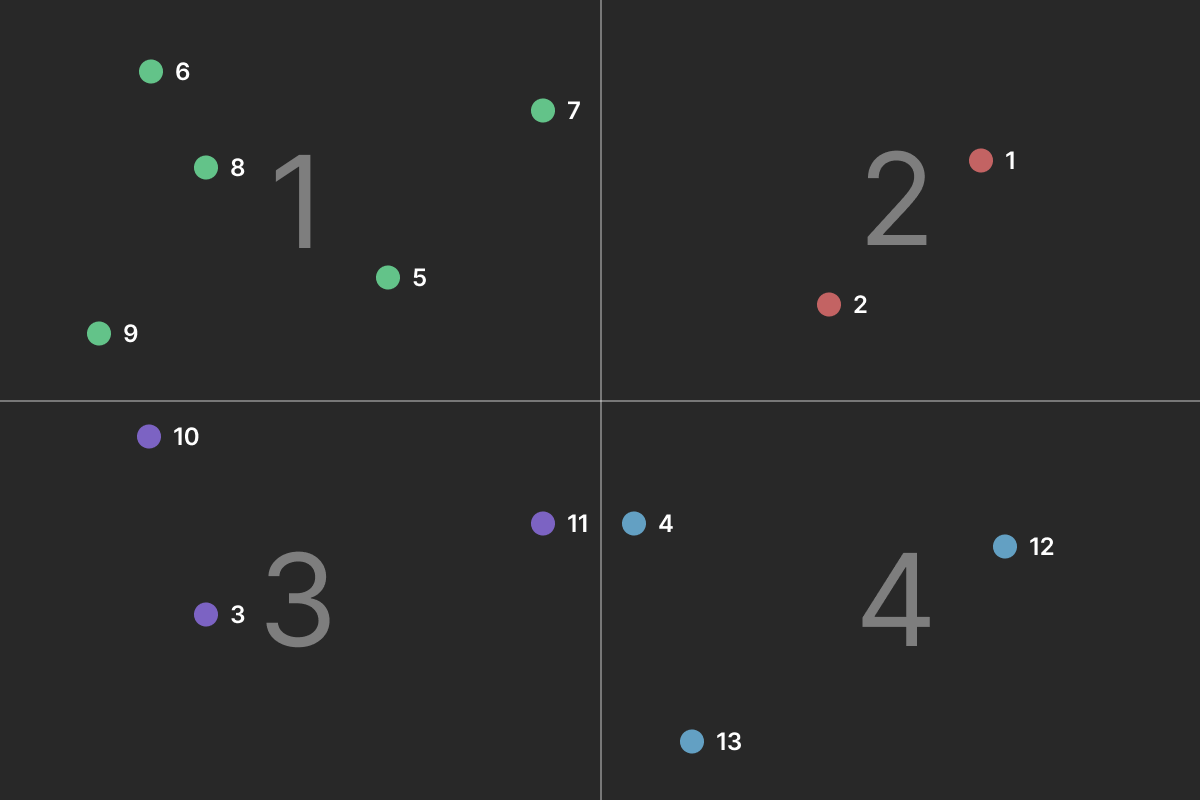
To create, for example, four folders, we can simply split the map into four distinct spaces. In our example, everything in the top left-hand corner belongs to the first folder. Thanks to the proximity concept in embeddings, all the elements will be related.
Yes, but that’s only four folders…
You’re right, we only have four folders. So with 100 000 articles, that’s still 25 000 items per folder. But remember, we are building a hierarchy of folders. So we can simply apply recursion to further divide the folders (i.e., we split each folder into four n times to build a tree).
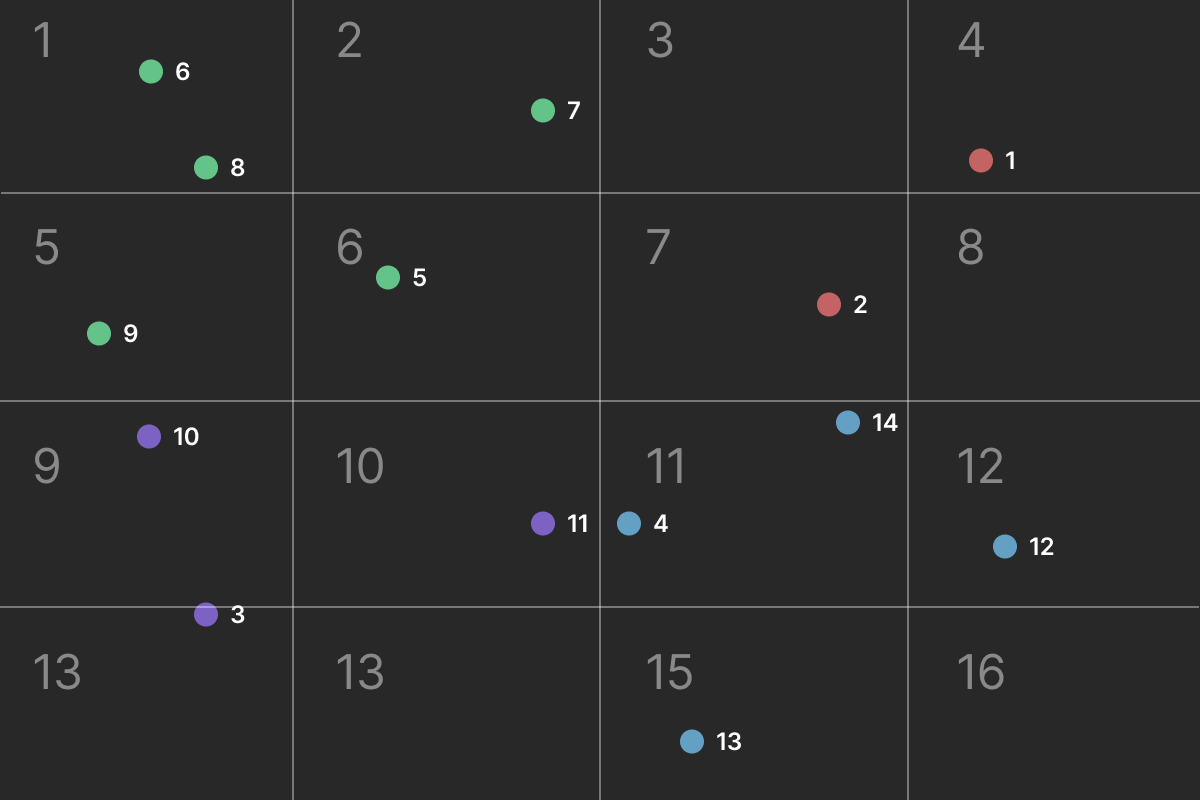
Now we have sixteen folders. By applying the algorithm again, we will have 64 folders. I’m no math genius, but eventually, there will be 4^n folders, where n is the number of times we applied the algorithm.
The fun part is that item 8 and item 9 are from the same subject and in the same folder
And now, how can we get the folder’s name?
Troubles never come alone, so now we are facing a whole new problem. I don’t like my approach to solving it. Therefore, if you have any better ideas, feel free to leave them in the comments section.
I’ve started by finding 5 tags related to each article using the tf-idf algorithm. As computer scientists, there are many topics we don’t understand, and so we simply glue libraries together. Let’s include this algorithm in this mess too. To summarize, you input the article’s text, and by comparing it to the other texts, the algorithm returns a list of keywords matching the content.
After running this algorithm, our next task is to find the names of the folders. To achieve this, we basically ask GPT-4 Turbo to retrieve the keywords recursively from the bottom to the top. We start with the more nested folders. Then, we compute the name of the parent folder using the keywords of the children. We repeat this process for the parent folder and so on. This is a suboptimal solution, I know, but I couldn’t find any better.

A criticism of my solution
To cite Loki,« No one good is ever truly good, and no one bad is ever truly bad ». And so is my solution.
The neighbouring issue
As seen earlier, we are arbitrarily splitting the vector space into zones. Therefore, two extremely related articles might find themselves in different folders because the boundary of one cell lies between them.
An example is when your PE teacher splits the group in two. While you are next to your friend, you can’t be with him because the beloved teacher chooses to draw the line between you and your buddy.
As you can see in our previous example, items 11 and 4 (in the 10-11 zone) are next to each other. However, they don’t belong to the same zone because a boundary is splitting them.
As a result, some folders don’t have all the ressources related to a theme. You have to explore the neighbouring folders to find them.
The uneven distribution
As mentionned earlier, we arbitrarily divided the directories into 4. However, the vectors aren’t distributed evenly. In the previous example, we can observe that certain zones have 2 items while others have none.
In a real-world scenario, we end up with folders with over 200 articles while some are mostly empty.
Conclusion
Well, that’s it. Thanks for reading the blog post. If you have any questions, don’t hesitate to comment.
Also, check the project here at https://alexandria-library.julienc.me/. By the way, I got so sick of JavaScript that the website only uses HTML and CSS the old-school way making it blazing fast /s.